From Mapping the Regulatory Mishmash to Product Intelligence

This blog was originally posted on 24th June, 2026. Further developments may have occurred after publication. To keep up-to-date with the latest compliance news, sign up to our newsletter.
AUTHORED BY MEG O’KEEFFE, SENIOR PRODUCT MANAGER, ADHERENT
How half a decade of feeling our customer’s pain became the foundation for our AI.
Before I became a Product Manager at Compliance & Risks, I led the Client Success team, worked with them to onboard many customers to C2P, our market leading product compliance platform, and advised on their regulatory processes. This history is important, because everything I think a regulatory monitoring product should do comes from sitting beside hundreds of compliance teams and helping make ours work for them.
This is one of a short series of posts from our team about what we’ve built and why. My colleague Shane, our other Senior PM, has written a companion piece, the view from the customer’s side of the table, drawn from years of conversations with compliance leaders, many of whom partnered with us to build our next-gen product. Mine starts where the learning started for me: with the team that knows our customer, and the product compliance world, better than most in the business.
Part One: The Regulatory Mishmash
Twenty years of expert curation is a strange beast. Our Regulatory Expert team at Compliance & Risks built the world’s biggest product regulatory database one regulation, and one data point at a time, and our data model grew with them organically. Components. Products. Categories. Policy Areas. Materials. Chemicals. Components. Attributes. Dates. Relationships. Limits. Targets. All of it interlinked, all of it carefully maintained, and all of it shaped by whoever needed the next piece of data created for the next regulation.
It was – and still is – the richest set of regulatory data in existence. But when customers arrived with a long list of their own products and asked the perfectly reasonable question “which regulations apply to me?”, getting to the right answer was a case of knowing our regulatory data model inside out, and learning everything there is to know about the customer’s products.
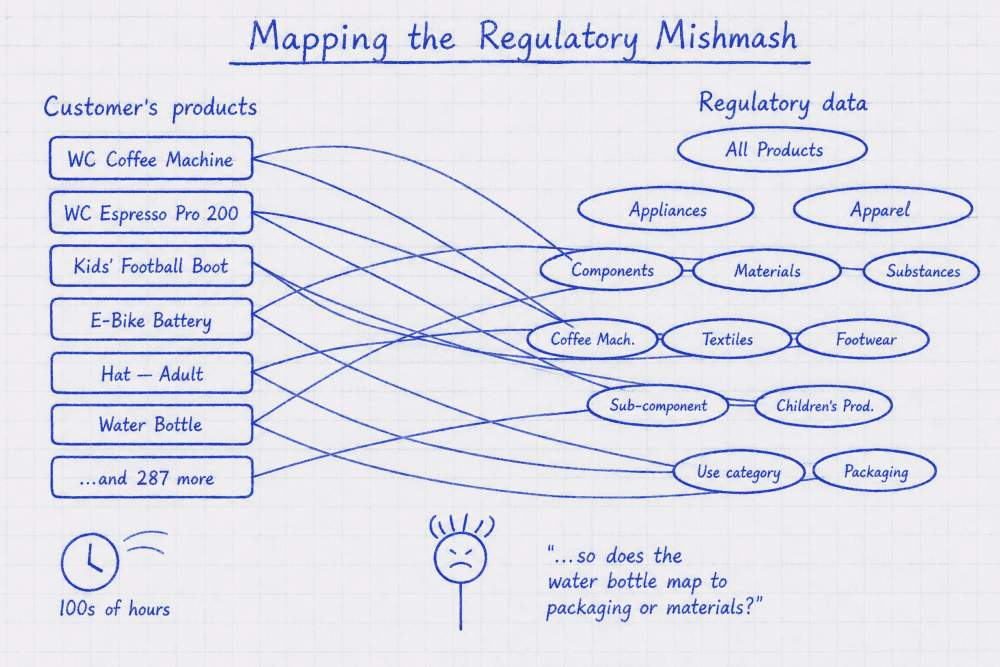
Figure 1. What “onboarding a customer” looked like .
We would sit down with the customer’s product list – often several hundred SKUs and categories – and the CS team would meticulously map each one into our data model. A water bottle: is that food contact, packaging, a consumer product, or a children’s product, or all three? An e-bike battery: battery, electrical equipment, or both? The Espresso Pro 200: appliances → coffee machines, but also components, pressure equipment, metals and probably plastics.
Hours and hours. Days, for the bigger customers. Then once the mapping was done, we’d layer everything else on top: substance filters, regulation-name filters, regulatory topic filters, geography filters. Filter on filter on filter, all to get to an accurate list of regulations for our customer.
The closest of our early customers did this with us, side by side. They felt the pain, and they helped us refine it, because – even with some irrelevant content – it was still the best solution out there for monitoring regulations that actually mattered to them. About fifty percent of what we returned was irrelevant, and about fifty percent was gold, still much better than any other solution our customers could find out there. That fifty percent was the number our own teams were quietly working to improve for years.
“Regulatory mishmash” is a word I use about the problem, not about C2P itself, C2P has been doing the hardest job in the industry brilliantly for twenty years. But anyone who’s sat through an onboarding session knows that someone being tasked with creating a mapping system between any customer product in the world and the vast regulatory landscape, would do very well to learn from our Client Success team.
Part Two: “The Mind of the Product”
Somewhere around 2021 we started circling a different way of looking at things, rather than thinking with the regulation data first, what if the product had its own mind. We know engineers describe a product by how it’s made: a bill of materials, a CAD drawing, a supplier list, but regulators don’t regulate the way an engineer designs & assembles. They regulate intended use, who the user is, who must be protected, what substances are present, what claims are being made, where it’s sold, who is responsible.
So we started asking: what if a product knew how it was regulated? What if the deep subject-matter expertise that lives inside compliance teams – the expert who can think about a product and a regulation at the same time and instantly see where they touch – what if a product could carry that knowledge with it?
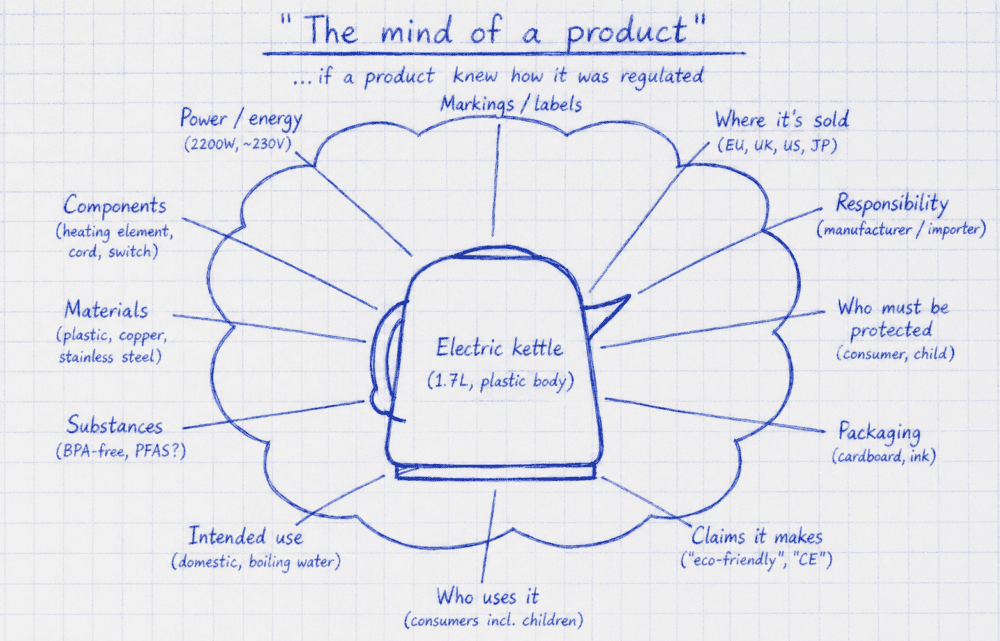
Figure 2. The “mind of the product” – every attribute a regulator might care about, hanging off the thing itself.
In 2025, when we set about building our next-gen product, this wasn’t a new idea, and we had had a few good runs at it over the years, but every time, we hit the same wall.
Structured, manually created regulatory data; controlled, queryable, expert-curated structured data. The exact thing that made our regulatory content the best in the world was also what prevented us getting to a “product first” solution. To do this manually we had to map every requirement inside a regulation to every possible piece of customer data it might touch – and on the customer’s side, from thousands of data points across regulations and requirements, return only the relevant ones, without losing the signal in the noise. Doing this manually meant thousands and thousands of hours of regulatory data mapping, meaning we had to slowly grow our data set by sector, and our customers were looking for a product first solution sooner.
Part Three: Why This Time is Different
When new tech arrived – Large Language Models that could reason over unstructured text, agents that could be orchestrated, embeddings that let us hold relationships that were never expressible in our traditional database – we recognised something most of the market didn’t. The opportunity wasn’t to throw away our data and start over with an LLM. The opportunity was to layer all of this new capability on top of twenty years of expert-curated structured data.
Everyone else racing into regulatory AI is starting from a blank page, pointing a model at the open internet and hoping it gives the right answers. We’re not. We’re starting from the biggest product-regulatory database in the world, with the relationships between regulations, requirements, products, components, substances, topics, dates, geographies already put in place by experts who do this daily.
So we set about encoding our collective regulatory intelligence into this next generation product. We paired our regulatory experts with our AI and engineering teams, and together they built something that had never quite been possible before: a way to know exactly which regulations apply to specific products, know when something changes, and know what to do about it. The outcome was a solution with three specialist layers, or AI agents, each handing off to the next.
Throughout the rest of this post, I use the term “agent” to mean an AI based automated process that thinks and acts on the user’s behalf – not a human representative.
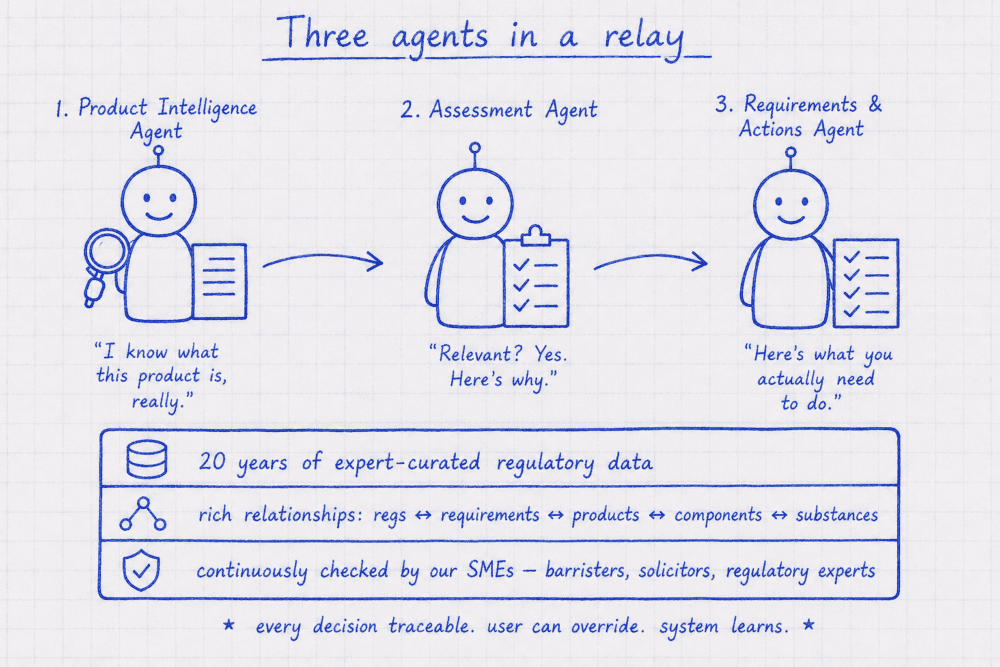
Figure 3. Three agents, one handoff. Built on the foundation we’ve spent twenty years curating.
1. The Product Intelligence Agent
This is the one I’m most proud of, because it’s the one I’ve been waiting five years for. The Product Intelligence Agent imitates the way a compliance SME inside a company thinks about a product. It understands the regulated ins and outs of the product: what it contains, how it’s used, what components and sub-components are inside it, who uses it, what substances and materials are present, what claims it makes about itself, who’s responsible for placing it on the market, who needs to be protected from a regulator’s point of view. It is, in effect, the “mind of the product” we’d been sketching on whiteboards for years, finally made real.
It hands that product intelligence picture to the next agent.
2. The Assessment Agent
The Assessment Agent takes the product intelligence picture and decides, for each regulation, whether it’s relevant. Because the product picture going in is so much richer than a product name or engineering spec, the assessment that comes out is too. When our AI team first stress-tested this approach against children’s and adult apparel in the African market, we ran 467 regulations through the pipeline and came out with 39 confirmed applicable. That sort of reduction, and the rationale tracing each decision back to the regulation and product itself, is genuinely new, and extremely valuable, for the compliance industry.
3. The Requirements & Actions Agent
Relevant regulations on their own are still just reading. So the third agent takes the applicable set, and the “mind of the product” and extracts every relevant requirement, then converts each one into a plain-English business action – something a person can actually do to gain compliance. This is what customers in our early test phases kept telling us they’d never seen before. One of our design partners put it this way after their very first walkthrough:
“Plugging in a new product and having it tell us what we need to do to sell legally, this blows away [the competitor] – it’s orders of magnitude better.”
– Director, Product Environmental Compliance, early testing customer
Part Four: Why We Trust It, and Why You Should Too
There are three reasons this works, and they’re the reasons I think we have a real, defensible edge.
- It sits on top of expert data, not in place of it. Every agent reasons over our curated content. That dramatically narrows the space of plausible answers and dramatically reduces the ambiguity that other LLMs and AI tools entering this market are still openly wrestling with.
- It’s continuously tested by the people who built the data in the first place. Our SMEs – barristers, solicitors and regulatory experts who extract regulations from across the globe for our database every day – are reviewing the AI’s decisions in batches against a golden dataset they themselves created. When the AI disagrees with a human expert, we go and look. That feedback loop is something a pure-AI startup simply cannot replicate.
- Every decision is traceable. We know compliance people, they will not trust a tool and they should not trust a tool that cannot show its work. Every output in the Adherent traces back to the exact regulation, the exact citation, and the attribute of the product that drove the decision. And the user can override any of it, any time. The system doesn’t sulk when you do; it learns. Every correction, every added piece of information about the product, updates the product’s mind and makes the next assessment smarter.
Half the regulations going into a project being noise was the price of admission for years. With this release, that ratio flips. We’re seeing customers go from staring at thousands of regulations to working through dozens of relevant ones – each with a reason, each with a citation, each with clear action.
If you want to see Adherent, we’re running early-access demos every week. Bring a product. Any product. Let’s see what it knows about itself.
A Small Note to the People We Sit Beside
If you were one of the Client Success team members who spent late nights mapping customer’s products and attributes, one of the customers who patiently helped us refine your scope, one of the product team or engineers who meticulously created the data structures we’ve built upon, one of our regulatory experts who patiently explained how regulations are broken down, over and over again, or one of the AI and engineering team who have made this their passion project over the last year……. the technology has finally caught up to us and allowed us to solve the problems we’ve been trying to for years.
This product release is yours.
Welcome to Adherent.
See Adherent in Action
Discover how agentic AI is reshaping product compliance for global enterprises.
Sign up to our
Monthly Market Insights
Our Connect Newsletter delivers the latest regulatory developments, trends and expert insights straight to your inbox.











